



Who Cares?
Does it really matter what you call your artifacts when you create them in a Fabric Workspace?
The Power BI Developer side of me didn’t really tend to give this much thought – Datasets would tend to be named after the business process they covered (e.g. Sales, Logistics etc…) and associated reports would describe the report’s intent (e.g. Weekly Sales Report, Delivery Adherence etc…).
Engineering Practices
But if I put my Data Engineer hat on, I’ve always been a fan of a robust naming convention.
In Azure infrastructure land there have been many words dedicated to this topic, with Microsoft even providing a formal guide.
And taking that a step further, most data teams I’ve worked in have also been keen to adopt similar patterns for Data Factory and Synapse Analytics components too. Our own Terry McCann wrote his own suggestions way back in 2017, and Data Platform MVP Erwin De Kreuk also has a good guide.
Clash of the Titans
With Fabric being a unified platform, the worlds of Power BI Developer and Data Engineer collide. So is a solid naming convention a good idea?
At Advancing Analytics, we say yes.
In fact, given the breadth of the platform and the variety of artifacts available for use in Fabric, it becomes even more important to have a strategy to be able to organise these items and make them quick and easy to identify.
Organising Artifacts
I’d previously toyed with the idea of separating out different types of artifact by having them in separate workspaces, but as it stands in the Fabric Public Preview, many of the artifacts need to be in the same workspace in order for them to interact with each other, which makes this a non-starter (and perhaps is a blessing in disguise as otherwise there’s a real danger of workspace sprawl with a hard to manage overhead).
Artifact types in a workspace do come tagged with a type and have a unique icon for each artifact type too, but the monochrome icon implementation, plus the need to scan the information across three columns in the display, doesn’t make this all that intuitive.
And there is also a method in the workspace where you can filter the artifacts displayed to show specific artifact types or Experiences (e.g. only show Data Engineering or Data Science), but again, the feature isn’t particularly obvious and even then, within a given type or product it can still be valuable to have some way of organising things.

What to call things?
So what should that naming convention be? Firstly, there are always some constraints. I’ve always found it infuriating that these rules can vary across Microsoft products. For example, a blob storage container can’t include any special characters and must be lower case. Azure SQL Databases can contain underscores and dashes, but not other special characters.
I couldn’t find any published guidelines for the cans and cannots of Fabric naming, but having done some experimenting, I found the most restrictive artifact to be Lakehouses, which only allow the use of underscores and alphanumeric characters, with the proviso that the first character must be a letter. Notebooks seem to be fair game, allowing spaces and special characters wherever you want. But in the interests of consistency adopting the most restrictive conditions across all artifacts is our preferred approach. Here's what we've found to work as a full naming convention after several months of experimentation during private preview.
Identifying Experiences
Firstly, group and identify artifacts based on the experience/product they belong to. There are currently 6 experiences in Fabric, with a seventh, Data Activator on the horizon. Our naming convention starts with a prefix to identify the experience.
|
Experience |
Abbreviation |
|
Power BI |
PBI |
|
Data Factory |
DF |
|
Synapse Data Engineering |
DE |
|
Synapse Data Science |
DS |
|
Synapse Data Warehouse |
DW |
|
Synapse Real-Time Analytics |
RTA |
|
Data Activator |
DA |
Identifying Artifact Types
Each Experience has a set of artifacts within it that you can create (bear in mind there are some overlaps between experiences too). An identifier for the artifact type makes up part two of our naming convention.
For Power BI, I don’t advocate that all artifacts need to have a naming convention applied. Certainly Apps and Reports, which are business/end user facing should continue to have business friendly and intuitive names.
However, it’s totally feasible that Datasets, Dataflows and Datamarts might sit amongst each other in the same place (and perhaps with other Fabric artifacts too), so the convention we've been establishing encompasses these artifacts to allow for consistency as well as flexibility depending on the approach employed.
|
Experience |
Artifact |
Abbreviation |
|
Power BI |
Dataset |
DS |
|
Dataflow |
DFL |
|
|
Datamart |
DM |
|
|
Data Factory |
Pipeline |
PL |
|
Dataflow |
DFL |
|
|
Synapse Data Engineering |
Lakehouse |
LH |
|
Notebook |
NB |
|
|
Spark Job Definition |
SJ |
|
|
Synapse Data Science |
Model |
MDL |
|
Experiment |
EXP |
|
|
Notebook |
NB |
|
|
Synapse Data Warehouse |
Warehouse |
WH |
|
Synapse Real-Time Analytics |
Database |
DB |
|
Queryset |
QS |
|
|
Eventstream |
ES |
Using these first two prefixes ensures that artifacts of the same experience and type will always appear together.
Adding More Context
The next recommendations allow you to give more context about the purpose of the artifact.
Adding an index part is a terrific way to be able to display grouped objects in a particular order. For example, for Data Factory pipelines you may have dependencies that mean pipelines need to run in a certain order. In which case DF_PL_100_ExtractData, DF_PL_200_TransformData and then DF_PL_300_LoadData, makes a nice pattern. Why a three digit number? Well, it gives the flexibility to add intermittent steps later without having to break the naming convention or rename everything.
If you’re following a medallion architecture, then including an index of 100 for the Bronze layer Lakehouse, 200 for the Silver layer and 300 for Gold helps show the progression of the data through the layers.
Which leads on nicely to the next element, which is to include the target stage of your platform that the artifact relates to. If a Notebook is the second stage of loading data to your silver layer, this becomes DE_NB_200_SILVER_ for example – this allows you some flexibility with naming convention of course (perhaps your lake zones are RAW > BASE > ENRICHED > CURATED for example), so adding the name of the layer makes the intended use more explicit.
Next we can add a brief description. For Lakehouses this might be the subject of the data housed within it, for Warehouses that could be the process you are trying to analyze, for Data Science artifacts it can describe the use case and the thing you want the model to predict.
Finally, with the stamp of approval of our very own Data Science aficionado Tori Tompkins, for Data Science Model artifacts we recommend adding a suffix to indicate the type of algorithm used. A list of common Machine Learning algorithms is included below:
|
Algorithm |
Abbreviation |
|
Decision Tree |
DT |
|
Random Forest |
RF |
|
Logistic Regression |
LOR |
|
Linear Regression |
LIR |
|
Support Vector Machines |
SVM |
|
K Nearest Neighbours |
KNN |
|
XGBoost |
XGB |
|
Light GBM |
LGBM |
|
Neural Net |
NN |
Additionally, including the Experiment/Use Case that a Data Science Notebook is being used for as a prefix to the description is a further way to group artifacts together.
The End Result
Putting all these parts together gives you the following:
|
Experience |
Artifact |
Index (optional) |
Stage (optional) |
Description |
Suffix (optional) |
|
PBI |
DS |
Sales |
|||
|
PBI |
DFL |
Sales |
|||
|
PBI |
DM |
Sales |
|||
|
DF |
PL |
100 |
BRONZE |
SourceToBronze |
|
|
DF |
DFL |
200 |
SILVER |
BronzeToSilver |
|
|
DE |
LH |
100 |
BRONZE |
WideWorldImporters |
|
|
DE |
NB |
100 |
GOLD |
SilverToGold |
|
|
DE |
SJ |
100 |
GOLD |
SilverToGold |
|
|
DS |
EXP |
PropensityToBuy |
|||
|
DS |
MDL |
PropensityToBuy |
XGB |
||
|
DS |
NB |
PropensityToBuy |
HyperparameterTuning |
||
|
DW |
WH |
GOLD |
Sales |
Note that not all parts to the naming convention are required. It’s unlikely that a Power BI Dataset will have any dependencies to other Datasets, nor is it likely that a Dataset will be anything other than the last mile of the platform, so an index and stage part don’t make sense here.
Something like a Machine Learning model may be part of a pipeline (say adding a risk score to a customer record) in which case, adding an index and stage may make sense… or it might be stand alone and not makes sense.
Use the naming convention parts according to your needs.
Using underscores to separate each part, a finished result looks something like this:
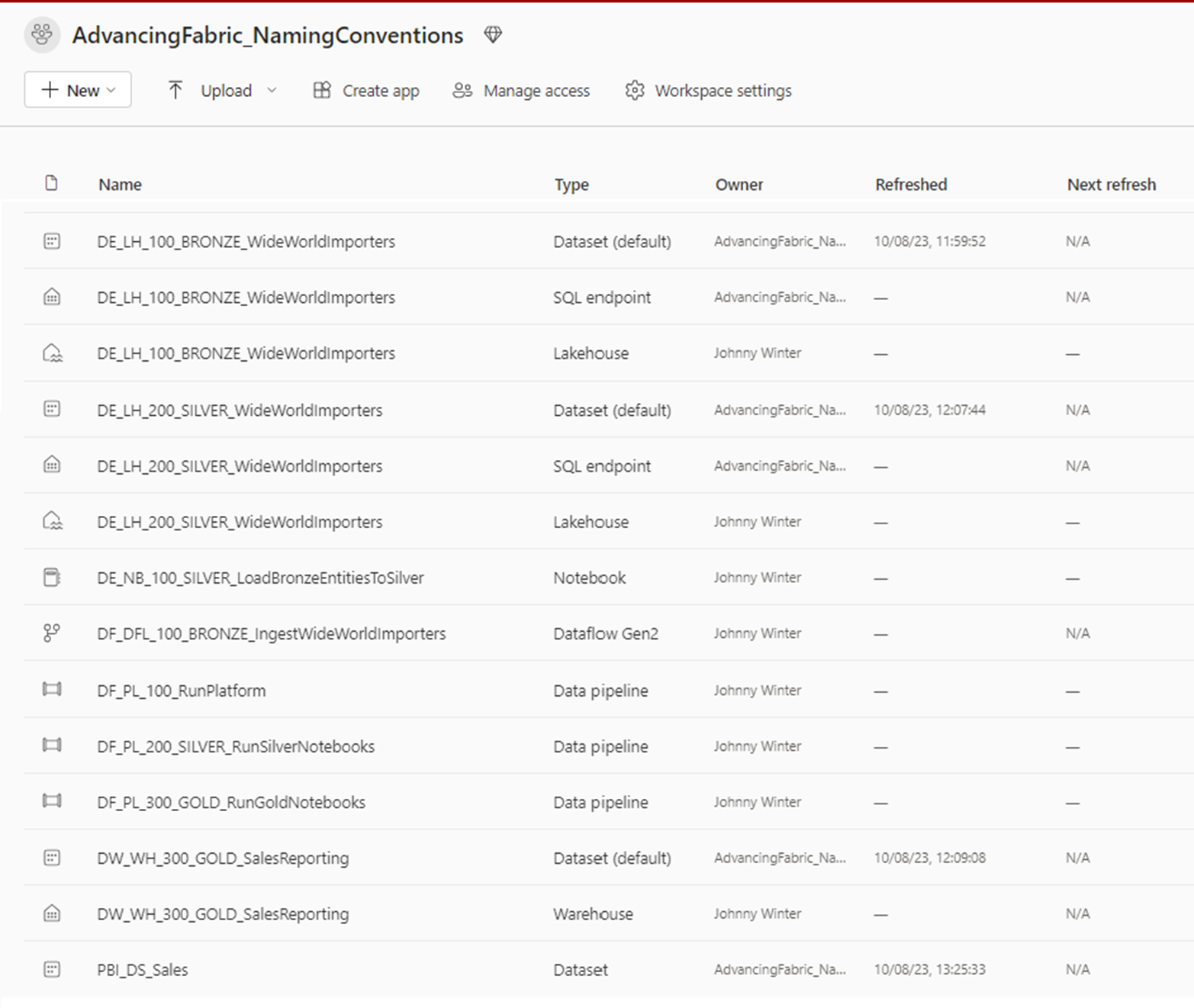
Note, that Lakehouse and Warehouse artifacts automatically create a default Dataset and SQL Endpoint as well, with currently no way to rename these.
Final Thoughts
Of course Fabric is still in Public Preview and the landscape may well change. Overtime, new experiences and artifacts may become available. And more navigation options might be revealed too. I heard a rumour that they may add support for creating folders in workspaces, which would be another fantastic way to organise. And perhaps the cross-workspace experience could happen too, so the option to separate using workspaces might one day become viable.
Policing adherence to any naming convention will always be hard. And given the self-service nature of a platform like Fabric, could well be nigh on impossible. Getting the balance right between technical naming conventions used by engineering personas and business friendly naming for more consumer based artifacts, is also another consideration and you may decide to draw the line in a different place on that spectrum - we never needed a Power BI naming convention before, so do we really need one now?
And perhaps we don’t really want the implementation of a strict naming convention to be a barrier to our citizen developers creating their own artifacts. I was recently encouraged by Chris Wagner to embrace the chaos of Fabric Workspace governance.

However, a recurring theme that I think we’ll see as Fabric evolves is Microsoft’s mantra of “Discipline at the core, flexibility at the edges” – with this in mind, I think applying a well thought out naming convention for Fabric artifacts to your widely used, centralized, enterprise level artifacts is a great idea. You could even make adherence to naming conventions part of the criteria for artifact certification.
Governance of Fabric is, for the meantime at least, a topic for another day.
Now you have a guide on how to name your artifacts, you need to go out there and create some! Need some help with that? If you want to have a discussion on how Fabric could benefit your organisation, please feel free to get in touch. You should also check out our current Fabric Proof of Concept offering.