




Image from Financial IT
Being able to detect fraud is one of the major issues faced by companies in this present age. With the evolving nature of technology, fraud has also been evolving in that regard and has become harder for companies to detect. The effect of fraud can be so devastating that it has caused many companies major losses or forced them to shut down.
Fraud is one of the most experienced crimes in the UK, according to the UK Office for National Statistics, in the year ending December 2020, fraud was the second most experienced crime in England and Wales, after theft.
In that year, there were an estimated 3.8 million incidents of fraud experienced by adults aged 16 and over in England and Wales, compared to 5.2 million incidents of theft (UK Office for National Statistics, 2021). It’s worth noting that these figures only include incidents that were reported to law enforcement or otherwise came to their attention, so the true number of fraud cases could be higher.
According to a report by the UK’s National Audit Office (NAO), fraud against the public sector alone is estimated to cost the UK government between £31 billion and £49 billion per year (National Audit Office, 2020). This includes fraud against government departments, local authorities, and the National Health Service (NHS).
In addition, the private sector also incurs significant losses due to fraud. The annual cost of fraud to UK businesses is estimated to be around £140 billion, according to a report by the Centre for Counter Fraud Studies at the University of Portsmouth (Centre for Counter Fraud Studies, 2018).
Overall, the total cost of fraud in the UK is likely to be in the tens of billions of pounds each year and maybe even higher when unreported or undetected fraud is taken into account.
The most common type of fraud in the UK is financial fraud, which includes credit card, insurance, tax, and loan application fraud among others. About 74% of fraud occurs within the private sector.
To reduce the amount of fraud, a rule-based system combined with Machine Learning could be the best approach.
RULE-BASED SYSTEM:

Image from Researchgate
This is a common system used by many financial companies already. It involves deriving a set of rules based on human expertise or domain knowledge and is designed to mimic the decision-making processes of human experts. For example, a rule-based system for a bank would include rules like “if the available balance is less than withdrawal amount, reject withdrawal”.
The rule-based system can be used in a wide range of applications, including fraud detection, diagnostic systems, decision support systems, and more.
There are 4 basic components of a rule-based system:
· The set of rules, more like the knowledge base.
· An inference engine, stands as the interpreter which infers information and takes action based on the inputted data and the rules.
· A temporary working memory.
· A user interface through which data can be inputted and sent out.
As good as a rule-based system may sound, there are limitations involved when it comes to combatting fraud.
LIMITATIONS OF A RULE-BASED SYSTEM:
· Limited flexibility: Rule-based systems’ capacity to respond to fresh or developing fraud patterns may be constrained by the fact that they are created to adhere to a set of pre-defined rules. This implies that they might not be able to identify more sophisticated or intricate fraud schemes that do not adhere to the established rules.
· False positives: When a genuine transaction or activity is mistakenly labelled as fraudulent, rule-based systems are susceptible to producing false positives. This may result in a large number of false alarms that require time-consuming and expensive investigation.
· Lack of scalability: It may be challenging for rule-based systems to adapt to larger datasets or more intricate fraud detection scenarios. This is because each new rule must be manually coded and tested, a process that can get more time-consuming and prone to errors as the number of rules increases.
To handle the effect of the limitations of a rule-based system regarding detecting fraud, the combination of both the rule-based system and Machine Learning as a hybrid system would be a better approach.
MACHINE LEARNING FOR FRAUD DETECTION:

Image from Forbes
Machine learning has become a popular approach for fraud detection due to its ability to learn and adapt to new patterns of fraudulent activity. Here are some ways in which machine learning can be used for fraud detection:
· Anomaly detection: Machine learning algorithms can be trained to recognise patterns of typical behaviour and flag transactions or activities that dramatically differ from those patterns as possibly fraudulent. This method is very good at identifying fraud tendencies that haven’t been observed before.
· Predictive modelling: Models that assign a risk score to each transaction or activity based on a variety of factors and past data can be created using machine learning algorithms. This can lessen the number of false positives and assist in prioritising suspicious transactions for further investigation.
· Natural language processing: Machine learning algorithms can be used to analyze unstructured data, such as text-based communications or social media posts, to identify patterns of suspicious behaviour or activity.
· Network analysis: Machine learning algorithms can be used to analyze large networks of interconnected entities, such as customers, accounts, and transactions, to identify patterns of suspicious activity. This approach can be particularly effective at detecting complex fraud schemes involving multiple parties.
BENEFITS OF A HYBRID SYSTEM IN DETECTING FRAUD:
A hybrid system that combines the strengths of both rule-based systems and machine learning can offer several benefits in detecting fraud. Here are some of them:
· Increased accuracy: Rule-based systems can be highly accurate at detecting known and pre-defined types of fraud, while machine learning can discover more complex and evolving fraud patterns that may not be caught by pre-defined rules. Combining these two approaches can lead to a more accurate and comprehensive fraud detection system.
· Improved scalability: Rule-based systems can be challenging to scale up as data volume and the number of fraud patterns grow as new rules must be defined and tested manually. On the other side, machine learning can scale up more quickly since it can adapt to new fraud patterns and learn from fresh data without the need for human interaction.
· Transparency: Since rule-based systems are built on explicit, previously specified rules, they are frequently very transparent as well as easy to understand. On the other side, machine learning models might be more intricate and challenging to explain. A hybrid system can provide both transparency and accuracy by striking a balance between these two approaches.
· Loss reduction: By combining both approaches, the accuracy of detecting fraudulent transactions is improved, thus reducing the amount lost to fraudulent activities.
· Reduced false positives: Rule-based systems can be prone to generating false positives, which can be time-consuming and costly to investigate. Machine learning can help to reduce the number of false positives by learning from historical data and identifying patterns that are more likely to be associated with fraudulent activity.
DEVELOPING A HYBRID SYSTEM FOR FRAUD DETECTION
In developing this hybrid system, sets of rules are required as well as a machine learning model. I would be making use of a vehicle insurance dataset from Kaggle in this demonstration.
The dataset can be downloaded from this link: https://www.kaggle.com/datasets/shivamb/vehicle-claim-fraud-detection
The ML model would be built using a random forest classifier on Azure Databricks using Pyspark.
Note: This code was written using Pyspark on Databricks, for other IDE you would need to import spark session.
import numpy as np # array, vector, matrix calculations import pandas as pd # DataFrame handling from pyspark.ml.feature import OneHotEncoder, StandardScaler, VectorAssembler, StringIndexer, Imputer from pyspark.ml.classification import RandomForestClassifier from pyspark.ml import Pipeline import mlflow import mlflow.pyfunc import mlflow.spark import pyspark.sql.functions as f from pyspark.sql.types import * from pyspark.ml.evaluation import BinaryClassificationEvaluator
We then read the file into a spark data frame. The file was downloaded directly from Kaggle and stored in a filestore on Databricks.

Display of spark_df
The necessary columns were then selected for the model development.

The data was then processed by creating a pipeline to scale numerical values and encode the categorical values for model development.
execlude_from_df= ["FraudFound_P"]
#the predictors, of all types
ex_df= [item for item in df.columns if item not in execlude_from_df]
to_encode= [col[0] for col in df.select(*ex_df).dtypes if col[1]=='string']
numerical_cols= [col[0] for col in df.select(*ex_df).dtypes if col[1]!='string']
pipe_stages= []
# all string(categorical) variables will be encoded into numbers, each category by frequency of label
sindexer= StringIndexer(inputCols= to_encode,
outputCols= ["indexed_{}".format(item) for item in to_encode],
handleInvalid='keep',
stringOrderType='frequencyDesc')
pipe_stages += [sindexer] # must add each step to the Pipeline
# dummy numerized strings into a sparse vector.
ohe= OneHotEncoder(inputCols= ["indexed_{}".format(item) for item in to_encode],
outputCols= ["indexed_ohe_{}".format(item) for item in to_encode],
handleInvalid='keep',
dropLast=True)
pipe_stages += [ohe]
# impute missing numerical values, with the median (though bad practice)
#imp= Imputer(inputCols= numerical_cols,
# outputCols=['imputed_{}'.format(item) for item in numerical_cols],
# strategy= 'median')
#pipe_stages += [imp]
# create the un-standardized features vector
assembler= VectorAssembler(inputCols= ["indexed_ohe_{}".format(item) for item in to_encode] + numerical_cols,
outputCol= "features",
handleInvalid="keep")
pipe_stages += [assembler]
# scale all features. Maybe you want to do this Before encoding the string columns?
ss= StandardScaler(inputCol="features",
outputCol="features_1",
withMean= False,
withStd=True)
pipe_stages += [ss]
pipe= Pipeline(stages= pipe_stages)
We then transform the data frame by applying the pipeline to it.
df_fit= pipe.fit(df) df= df_fit.transform(df) df.display()
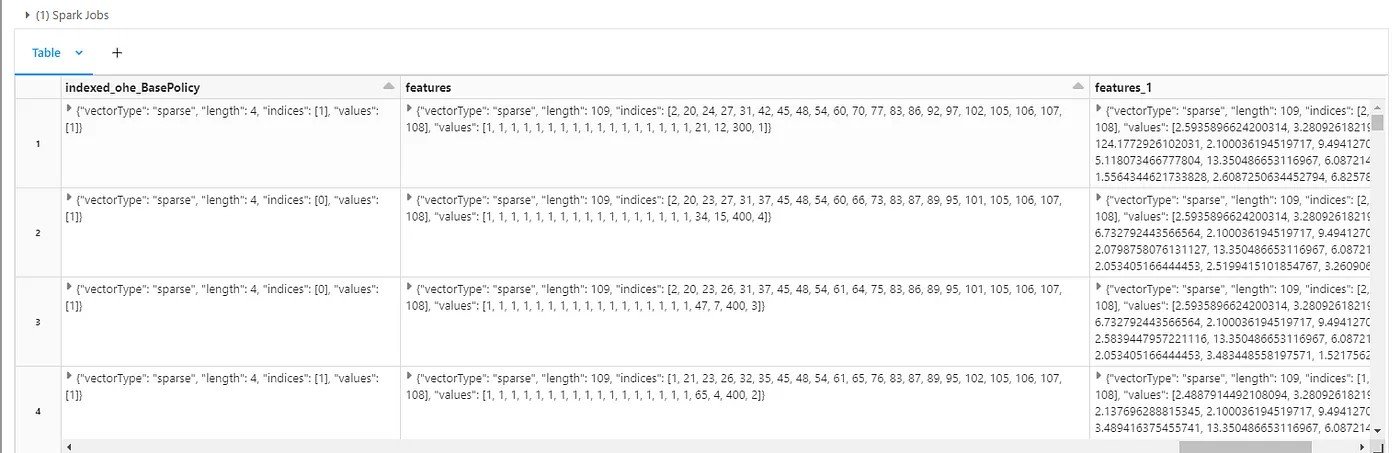
The pipeline uses a vector assembler to create features that would be used to train the model.
train, test= df.randomSplit([0.75, 0.25], seed=42)
rfc= RandomForestClassifier(numTrees=70,
maxDepth=3,
labelCol='FraudFound_P',
featuresCol="features_1",
seed=42)
rfc_model= rfc.fit(train)
The dataset can then be split into train and test with the train having 75% of the dataset. The random forest parameters are then defined. We then train the model by applying fit to the training dataset.
predDF= rfc_model.transform(test)
# Instantiate the evaluator
# similarly with MulticlassClassificationEvaluator
bce= BinaryClassificationEvaluator(rawPredictionCol= "rawPrediction",
labelCol="FraudFound_P",
metricName= "areaUnderROC")
# Apply
bce.evaluate(predDF)
To evaluate the performance of the model, the model was first used to predict the outcome of the test dataset. A binary classification evaluator was then used to calculate its ROC-AUC which gave a score of 0.82, which is fair. When it comes to business use, a model with higher performance would be required. In order to achieve this, the model would need to be further fine-tuned for better performance.
One major importance of using Databricks aside from its ability to provide distributed computing using clusters is the ability to track models using MLflow. MLflow can be used to register your models as well as other artifacts like its accuracy and parameters involved in developing the model. MLflow can also be used to monitor your model from dev all the way through to prod.
For the purpose of this blog, the model was also registered to MLflow, so it can be recalled for inferencing in the fraud orchestrator.
# Start an MLflow run
with mlflow.start_run(run_name="RF Model_Fraud") as run:
# Log the pipeline model as an artifact of the run
mlflow.spark.log_model(rfc_model, "model")
# Set run's metadata
mlflow.set_tag("model_type", "RandomForestClassifier")
mlflow.set_tag("Accuraccy", bce.evaluate(predDF))
# Log the run id and artifact location
run_id = run.info.run_id
artifact_location = mlflow.get_artifact_uri()
print(f"Run with ID: logged to MLflow")
print(f"Artifact location: ")
The model was registered as RF MODEL_FRAUD.
The other aspect of this hybrid system is the rules used to detect fraud. When it comes to rules, most businesses have rules pertaining to their businesses. This set of rules are created based on human experience and intuition.
To create rules for the blog, SHAP explainer was used to explain the features of the model that affect the model’s prediction the most.
from sklearn.ensemble import RandomForestClassifier
import numpy as np
import shap
import pandas as pd
new_cols = [f.col(c).alias(c.replace('index_', '')) if c.startswith('index_') else f.col(c) for c in df.columns]
pandas_df = (
df.select(
numerical_cols
+ ["indexed_{}".format(item) for item in to_encode]
)
)
new_cols = [f.col(c).alias(c.replace('indexed_', '')) if c.startswith('indexed_') else f.col(c) for c in pandas_df.columns]
cleaned_df = pandas_df.select(*new_cols).toPandas()
model = RandomForestClassifier()
model.fit(cleaned_df, df.select("FraudFound_P").toPandas().values.ravel())
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(cleaned_df, check_additivity=False)
p = shap.summary_plot(shap_values[0], cleaned_df, show=False)
display(p)
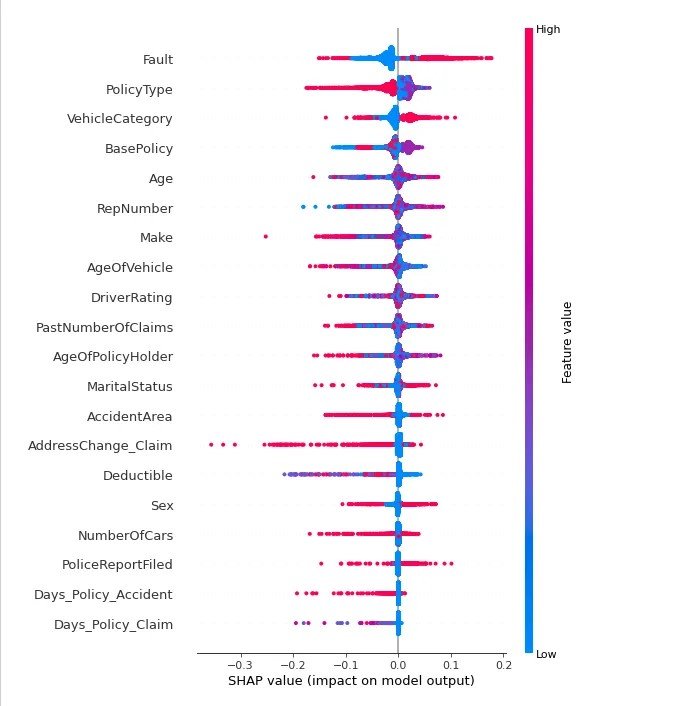
To create sample rules for this blog, rows with fraud were filtered out from the dataset and analysed based on the first five features from SHAP. The rules were created and used in the Fraud detection orchestrator. This has just been done for the purpose of this blog, usually, businesses have more complex and advanced rules pertaining to that business for detecting fraud.
#creating rule system for scoring
def rules(df):
# initialize score variable
total_score = 0
# Rule 1: if Fault = policy holder score 10 else 5
if df['Fault'] == 'policy holder':
rule1_score = 10
else:
rule1_score = 5
total_score += rule1_score
# Rule 2: if PolicyType = sedan score 10, if its collision score 7, if its peril score 5, else score 3
if df['PolicyType'] == 'Sedan - Collision':
rule2_score = 10
elif df['PolicyType'] == 'Sedan - Liability':
rule2_score = 7
elif df['PolicyType'] == 'Sedan - All Perils':
rule2_score = 5
else:
rule2_score = 3
total_score += rule2_score
# Rule 3: if VC = Sedan score 10, if its Sport score 5, else score 3
if df['VehicleCategory'] == 'Sedan':
rule3_score = 10
elif df['VehicleCategory'] == 'Sport':
rule3_score = 5
else:
rule3_score = 3 # no score if BP is not collision or peril
total_score += rule3_score
# Rule 4: if BP = Sedan score 10, if its Sport score 5, else score 3
if df['BasePolicy'] == 'Collision':
rule4_score = 10
elif df['BasePolicy'] == 'Liability':
rule4_score = 7
else:
rule4_score = 5 # no score if BP is not collision or Liability
total_score += rule4_score
# Rule 5: if age is between 24 and 27 score 5, if its between 28 and 34 score 7 else if age is between 35 and 42 score 10.
if 24 <= df['Age'] <= 32:
rule5_score = 8
elif 32 <= df['Age'] <= 40:
rule5_score = 10
elif 40 <= df['Age'] <= 48:
rule5_score = 6
elif 48 <= df['Age'] <= 56:
rule5_score = 3
else:
rule5_score = 0 # no score if age is outside the specified range
total_score += rule5_score
return total_score
def sensitivity(df):
if 40 <= df['score'] <= 50:
action = 'High'
elif 25 <= df['score'] <= 40:
action = 'Medium'
else:
action = 'low'
return action
def scores(df):
df=df.toPandas()
df['score']=df.apply(lambda x: rules(x), axis=1)
score=df['score']
df['action']=df.apply(lambda x: sensitivity(x), axis=1)
action = df['action']
return score,action
#setting up model function
def predict(uri,df):
logged_model = (uri)
# Load model
loaded_model = mlflow.spark.load_model(logged_model)
#process df
df = df_fit.transform(df)
# Perform inference via model.transform()
pred_df = loaded_model.transform(df)
return pred_df.select(f.col('prediction')).display()
The code above is the fraud orchestrator. The function “rules” contains the rules to be applied to the input data. We have created the function rules for outputting a score between 0–50. This score represents the confidence (based on domain knowledge) that the inputted data entry is fraudulent. A higher score gives greater certainty of fraudulent activity.
In a bank, rules can be used to stop a transaction, rules such as if the available balance is lower than the withdrawal amount requested, decline the transaction. But for a claim in an insurance company, such rigid rules might not be suitable. The rules described above are used to create a scoring system. If the total score lies between chosen thresholds, it would be classed as high, medium or low. When a claim results in high it's an indication that the claim needs to be passed to the fraud team for further investigation.
The rules function is applied by the score function to the input data, to provide a score to determine if it's possible fraud for further investigation.
The predict function then imports the registered model from Databricks MLflow and then uses it to predict if it's a possible fraud claim.
We created a sample input data to test the orchestrator.
data = [('Honda','Urban','Female','Single',21,'Policy Holder','Sport - Liability','Sport',12,300,1,'more than 30','more than 30','none','3 years','26 to 30','No','No','1 year','3 to 4','Liability')]
Test_df1 = Test_df.drop(f.col('FraudFound_P'))
Test_df2 = spark.createDataFrame(data,schema = Test_df1.schema)
Test_df2.display()

Dataframe of the input sample data
The input data was then used for scoring.
#Scores input for fraud detection scores(Test_df2)

The result from the scoring provided a score of 20 and states its sensitivity towards fraud is low.
#Predict fraud using model
predict('runs:/69697682f58048ac97a65baa5dd7622c/model',Test_df2)
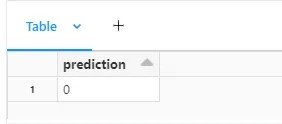
The model has also predicted the claim as non-fraudulent. Based on this insight decision can then be taken.
In summary, this hybrid approach provides a system that can be really helpful in detecting fraud. This approach makes it easier to highlight transactions that need further investigation before approval. This saves the business money and also helps prevent fraud.
Furthermore, when it comes to fraud detection, fraud techniques change over time. The model would need to be re-trained regularly to capture new patterns. Over time new insights can be captured from fraud predicted by the model to improve the rules.
I hope you had fun reading this and have learnt the benefits of this hybrid approach in detecting fraud.
REFERENCE:
-
Centre for Counter Fraud Studies, (2018). Annual Fraud Indicator 2018. University of Portsmouth. https://www.port.ac.uk/research/research-centres/centre-for-counter-fraud-studies/acf/acf-2018.
-
UK Office for National Statistics. (2021). Crime in England and Wales: year ending December 2020. https://www.ons.gov.uk/peoplepopulationandcommunity/crimeandjustice/bulletins/crimeinenglandandwales/yearendingdecember2020.
-
National Audit Office. (2020). Investigation into the government’s progress in reducing fraud and error in the benefit system. https://www.nao.org.uk/wp-content/uploads/2020/07/Investigation-into-the-governments-progress-in-reducing-fraud-and-error-in-the-benefit-system.pdf