



The world of machine learning is constantly evolving, and businesses today face many challenges in productionising machine learning models. From collecting and cleaning data to training, deploying, and monitoring models, the process of bringing machine learning into production is complex and time-consuming. The rise of machine learning has only added to these challenges as organisations seek to incorporate these advanced technologies into their operations. However, many organisations struggle to find a platform that can help them manage, develop and deploy machine learning models at scale. This is where Databricks comes in!
Databricks is a cloud-based platform for data engineering, machine learning, and analytics that provides a unified environment for data processing, machine learning, and analytics. With its user-friendly collaborative notebooks and distributed computing capabilities, Databricks provides an end-to-end solution for machine learning development and deployment.
Whether you're just getting started with machine learning, are a seasoned data scientist, or you're still on the fence about whether Databricks is right for you, here are ten reasons why Azure Databricks for Machine Learning rocks.
1.Cloud Integration
Databricks seamlessly integrates with Azure, AWS, and GCP, offering organisations the flexibility to choose the cloud platform that best fits their needs. Take Azure for example, Databricks integrates with Azure and its AI services such as Azure Machine Learning and Cognitive Services, enabling seamless access to existing capabilities in Microsoft technology and advanced AI capabilities. As a result, you can leverage the advanced AI capabilities offered by Azure to build and deploy machine learning models faster and with greater accuracy. In addition, Azure Databricks integrates directly with Azure Active Directory (AAD) security framework, allowing organisations to use existing credentials and authorisation for secure access to the platform. With no need for custom configuration, organisations can easily ensure the security and compliance of their machine learning workflows.

2. Support for Multiple Programming Languages in Interactive Workspace
Databricks offers a collaborative environment that supports team-based machine learning workflows and enables you to share models and data between team members. The powerful notebook environment provides integrated support for Python, R, Scala and SQL, making it easy to perform data analysis, prototyping, and experimentation. The platform's flexible and user-friendly interface makes it easy for data analysts, data engineers, data scientists and machine learning engineers to work together on a common platform using a programming language of their choice.
3. Distributed computing with Spark
Apache Spark is a distributed computing framework that enables you to process large amounts of data efficiently and at scale. By leveraging PySpark, the Python API for Spark, you can easily build and run large-scale machine learning models. This makes it an essential tool for businesses looking to operationalise machine learning, as it allows them to process large datasets, handle complex computations, and scale their models to meet their business needs.

4. Pandas on Databricks
There are two ways to use Pandas on Spark; Pandas UDF (User Defined Function) and Pandas API on Spark. Pandas UDF is a way to run Pandas code on Apache Spark. It allows you to take advantage of the power of Spark by processing large datasets in parallel. Pandas API on Spark is an evolution from the Koalas project that allows using Pandas syntax on Spark dataframes. The main advantage of Pandas API on Spark is that data scientists with Pandas knowledge can immediately be productive on Spark and also allows the ability to port code written in Pandas to Spark.

5. Feature Store
Feature store is a centralised repository for storing, managing, and serving features, which are pre-computed variables used as inputs to machine learning models. Databricks feature store fits seamlessly into the machine learning operations (MLOps) process, enabling enterprises to manage the entire ML pipeline from data ingestion to deployment in a centralised and organised manner. This is important for businesses looking to productionise machine learning as it streamlines the MLOps process and reduces the time and resources required to manage the ML pipeline. The feature store ensures that features are consistent, of high quality, and reliable, which is critical for the success of machine learning models.
6. Automate your Machine Learning lifecycle
The AutoML in Databricks provides a powerful way to automate parts of the machine learning process and reduce the amount of time and effort required to build models. With AutoML, data scientists can automate tasks such as feature engineering, model selection, and hyperparameter tuning, freeing up time and resources to focus on more valuable tasks such as data analysis and model development.

7. Managed by MLFlow
MLflow is an open-source tool that provides a comprehensive management solution for the lifecycle of machine learning pipelines and applications. As a part of the Databricks platform, data scientists can use MLflow for free and take advantage of its powerful features to track and reproduce experiments, manage models, and effortlessly deploy them to production. This integration of MLflow with Databricks makes it easier for businesses to effectively manage their machine learning pipelines and models, promoting consistency, quality, and reproducibility throughout the entire lifecycle.
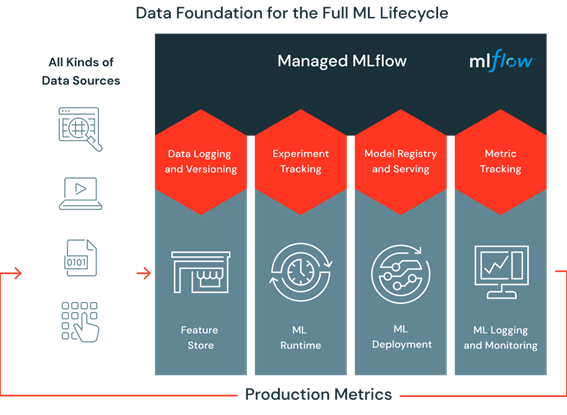
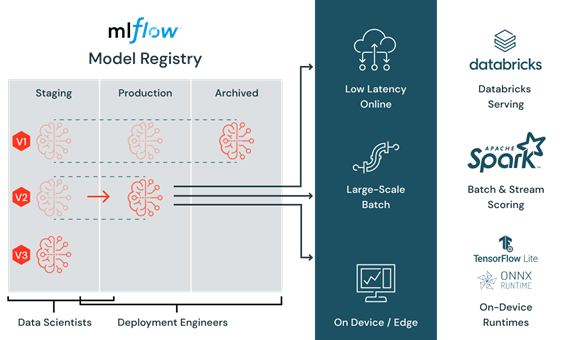
8. Model Deployment
Databricks provides a comprehensive solution for deploying machine learning models into production. The platform supports both batch and real-time inference capabilities, providing flexibility to run large-scale models in batch mode or process predictions in real-time, depending on the requirements of your use case. This built-in support for model deployment makes it easier to productionise your machine learning models and quickly realise the benefits of AI in your business.
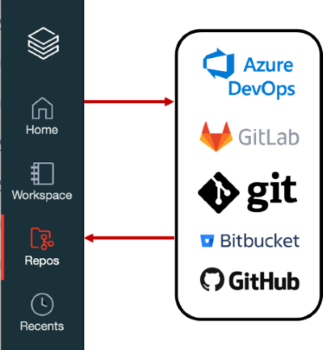
9. Databricks Repos
Databricks makes it possible to connect to your Git providers and import notebooks directly into the platform. This integration makes it easier to share and collaborate on code and helps streamline the machine learning development process. This integration can significantly improve your machine learning operations (MLOps) by allowing you to manage your code more effectively, reduce the risk of errors, and speed up the deployment process.
10. Integration with Popular Tools
Databricks integrates with popular machine learning libraries and tools, such as PyTorch, XGBoost, TensorFlow, and SciKit-Learn, making it easier to use your existing workflows. To leverage these tools, all you have to do is spin up a machine learning cluster, and these will be automatically installed and configured for you, eliminating the need for manual setup and configuration. This not only saves time and effort but also ensures that all members of the team are using the same environment and libraries, reducing the risk of compatibility issues and promoting consistency in results.

WRAPPING UP
Overall, Azure Databricks is an ideal platform for businesses looking to harness the power of machine learning and help overcome the challenges of productionising machine learning models. If you are looking for a platform to manage, develop and deploy machine learning models at scale, Azure Databricks is a great choice. With its cloud integration, flexible notebook environment, managed by MLflow, distributed computing with Spark, Pandas on Databricks, Feature Store, AutoML capabilities, built-in support for model deployment, and Databricks Repos, it has everything you need to build and deploy machine learning models.
