


Fabric Concurrency
Fabric has been in general availability for a couple of months now, I posted this blog before the Xmas and pretty much the second it was posted there was an update to Fabric concurrency! It shows that Microsoft are behind this product and improving it all the time. Now that the dust has settled on the new year I thought I would come back and update the blog. The good news is Microsoft has made concurrency slightly simpler and done away with reserved compute for different job types.
We can probably expect more updates to Fabric in the coming months so I’m sure this blog will probably be out of date again soon!
At Advancing Analytics we were lucky enough to have access to Fabric during its preview and started to develop our own Fabric accelerator. Feel free to contact us if you want to know more!
One of the most difficult things during this process for us was understanding how concurrency works and how we can run multiple notebooks at once without getting errors. It seemed like whenever we tried to run two notebooks at the same time, we would always get concurrency errors like this one.
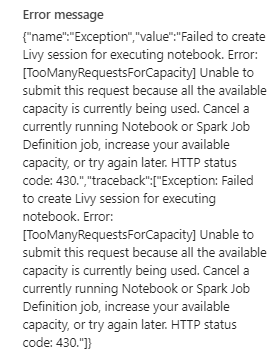
Fabric error message
The reason lies in the documentation in the snippet below.

Snippet from Fabric documentation
Currently this means if you exceed your capacity for interactive jobs, you will just receive an error message and your activity will fail. Currently this seems to be a real weakness with Fabric and it’s something I hope Microsoft will be fixing soon.
What is capacity?
If you are currently using Microsoft Fabric you will have some sort of capacity associated with your account. This will have a large impact on what you can run concurrently. If you are on a Fabric Trial, you will have access to a trial capacity and if you are paying you will be on a certain capacity tier based on how much you pay. The following diagram shows information about each level of capacity and the Trial. The Trial resembles F64 capacity but is apparently different in some important ways (More on that later).
This diagram is key to working out available Notebook concurrency and the method is thankfully simple.
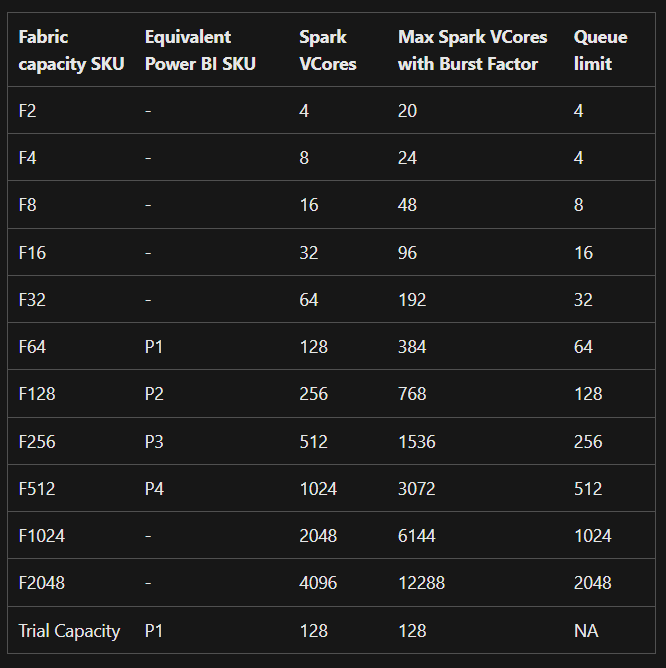
Table from Fabric documentation detailing different SKUs
The thing that tripped me up in the table is the Queue limit. I assumed that for paid capacities there was queueing and for the trial there wasn’t so therefore when I switched on a paid capacity, I would stop getting errors when I ran notebooks simultaneously as long as I wasn’t trying to run more notebooks than the queue limit I should be able to have at least that level of concurrency. This however wasn’t the case. The answer can be found in this line in the docs.

Snippet from Fabric documentation
This clearly states that queueing only works for batch jobs. Going back to an earlier snippet in the docs it says whenever interactive jobs exceed capacity they are throttled and error out.
What is an Interactive job compared to Batch?
Although compute is no longer reserved for Batch and Interactive jobs queueing is still only available for Batch jobs so it’s a bit puzzling why Microsoft has taken out the explanation of the difference between Batch and Interactive jobs from the docs. Luckily I have screenshots of the docs before they were updated.
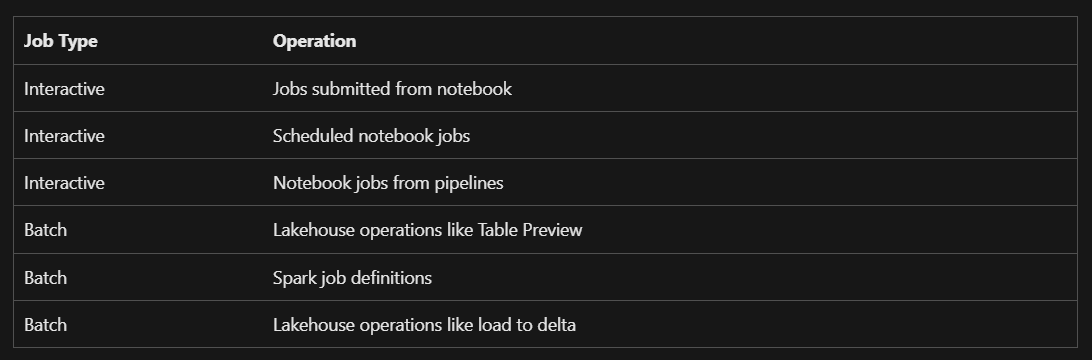
Table now missing from the Fabric documentation explaining which jobs are Batch and which are Interactive
From this we can see Notebook runs are always interactive, therefore they won’t be added to a queue and will simply fail if the capacity is exceeded. Really hoping this is something Microsoft will change at some point and I would be very surprised if queueing wasn’t enabled for all types of jobs very soon.
There is a simple way to work out how many notebooks you can run at once you just need to take certain things into consideration.
Spark vcores for your SKU
Cores are your compute and the main factor that will affect your concurrency limit is your capacity SKU as this will have an associated number of cores. To put it simply if you don’t exceed your maximum cores you shouldn’t run into problems.
Nodes in your pool
The default starter pool is set to auto scale up to 10 nodes. There is a good chance this will be overkill for your workload! If you use a custom pool, you can change this setting.
Number of vcores in a node
This will be affected by the node size.
Small = 4 cores
Medium = 8 cores
Large = 16 Cores
XLarge = 32 Cores
XXLarge = 64 cores
Degree of parellelism (DOP)
Degree of parallelism is what I am calling how many notebooks you want to run at once. For example, if you were using a pipeline with a for each that runs notebooks inside and the Batch count is set to 6 the degree of parallelism would be 6. Most of the time when making these calculations DOP is what you want to work out based on the other numbers available.
When thinking about degree of parallelism you should also think about whether you need to have any spark sessions able to run at the same as your pipeline which is running notebooks in parallel. You might decide you need a DOP of 8 consisting of a pipeline running notebooks with a Batch count set at 6 and two spark sessions.
Cores available = min cores
Cores needed = nodes x cores per node x DOP
It’s important to note because of the cores needed formula you can mix and match number of nodes and node size (cores per node) settings which will produce different levels of available concurrency.
To avoid errors cores available must always be greater or equal to cores needed.
Cores available ≥ Cores Needed
Let’s think about a couple of examples!
Talking about the trial capacity first as that is what I assume most people are using currently. The cores available in the trial capacity are 128.
If we stick with the standard starter pool our nodes in pool is 10 and node size is medium so vcores per node is 8. Therefore 128/(10 x 8) = 1.6
Our DOP is 1.6. DOP must always be a whole number (as we can’t run 0.6 of a notebook) so this must be rounded down to 1 meaning with a standard starter pool we can only run one notebook at once to remain within our interactive core limit.
If we change the starter pool to a custom pool, we can get a higher degree of parallelism though and run more things at once.
To get the highest DOP available you will need the least nodes and cores per node.
I recommend setting number of Nodes to no less than 2 though because there is an open issue with 1 node pools currently where they can take much longer to start up.
To get the fewest vcores per node as well we can select node size of small which will give a vcores per node of 4. Now our calculation is 128/(2x4) = 16
So with these settings we can get a DOP of 16! Enabling us to run 16 notebooks simultaneously without issues. Or 10 notebooks in a pipeline and 6 ad hoc sessions (using the same pool configuration).
It is important to remember that changing number of nodes and node size will have an impact on how long your notebooks take to run so you may have to play around with the settings and the DOP to get the sweet spot. I have generally found with notebooks that are loading data files in the <1GB range for a parquet file that a higher DOP is better for overall speed, but this will depend a lot on amount of data, what your notebook is doing and how your code is written.
Now let’s work out the possible DOP for a 4 node medium node size custom pool in F512 capacity.
Available cores = 1024
DOP = 1024/(4 x 8) = 32
Therefore, on F512 capacity with those settings we should be able to run 32 notebooks at once!
Other Considerations
In Fabric, compute is currently reserved in a pessimistic manner. Therefore, if you set up your pool with 1-10 nodes and a medium node size (i.e. the same as the default starter pool). 80 vcores will be “reserved” (10 Nodes x 8 vcores) as it will assume the worst in terms of how many are needed. I think it would be good if they changed this or at least made it clearer in the documentation.
There is also bursting to consider; bursting is a function where you can temporarily exceed your max cores by a factor of 3 but only for additional jobs (meaning you cannot exceed your max cores with a single job). So, if your min interactive cores are 128 with bursting, they will be 384. When bursting is applied the consequence will also be that later your compute is smoothed and when you are not using it at peak times there will be less available. I have also noticed in my testing that I still sometimes seem to get concurrency issues when I should be within the bursting limit so I would advise trying it for yourself and using with caution.
In terms of bursting on the trial it’s a bit confusing. According to the docs now bursting is not available on the trial capacity. I have managed to get 12 notebooks running concurrently and loading simple datasets on the trial without issues though so if you set up your pools in a certain way decent concurrency is still available on the trial even without bursting.
Overall, it can be a bit tricky to get your head around notebook concurrency in Fabric currently but recent updates have made things easier and more are sure to be coming soon. I will update this blog (Again) when they do.
Just remember your cores available and how many you are using though, and you should be fine!