




Following on from my previous post I wanted to cover off some more key topics that can really help your understanding of Spark and diving in to the Databricks Certified Associate Developer for Apache Spark 3.0 exam.
For more information on general assessment tips, great practice exams to take and other core topics, please see Part 1.
More Topics to Remember
Broadcast Variables & Accumulator Variables
Both of these are shared variables across the cluster, but what are the uses and differences?

Broadcast Variables
On a top level, Broadcast Variables are immutable (read-only) and shared amongst all worker nodes in a cluster. As they are accessible within every node this can improve read time.
Say we have a large dataset partitioned across the cluster which contains a RegionCode as one of the columns.
We want to lookup the RegionName from Table 1 to incorporate it in to the main dataset.


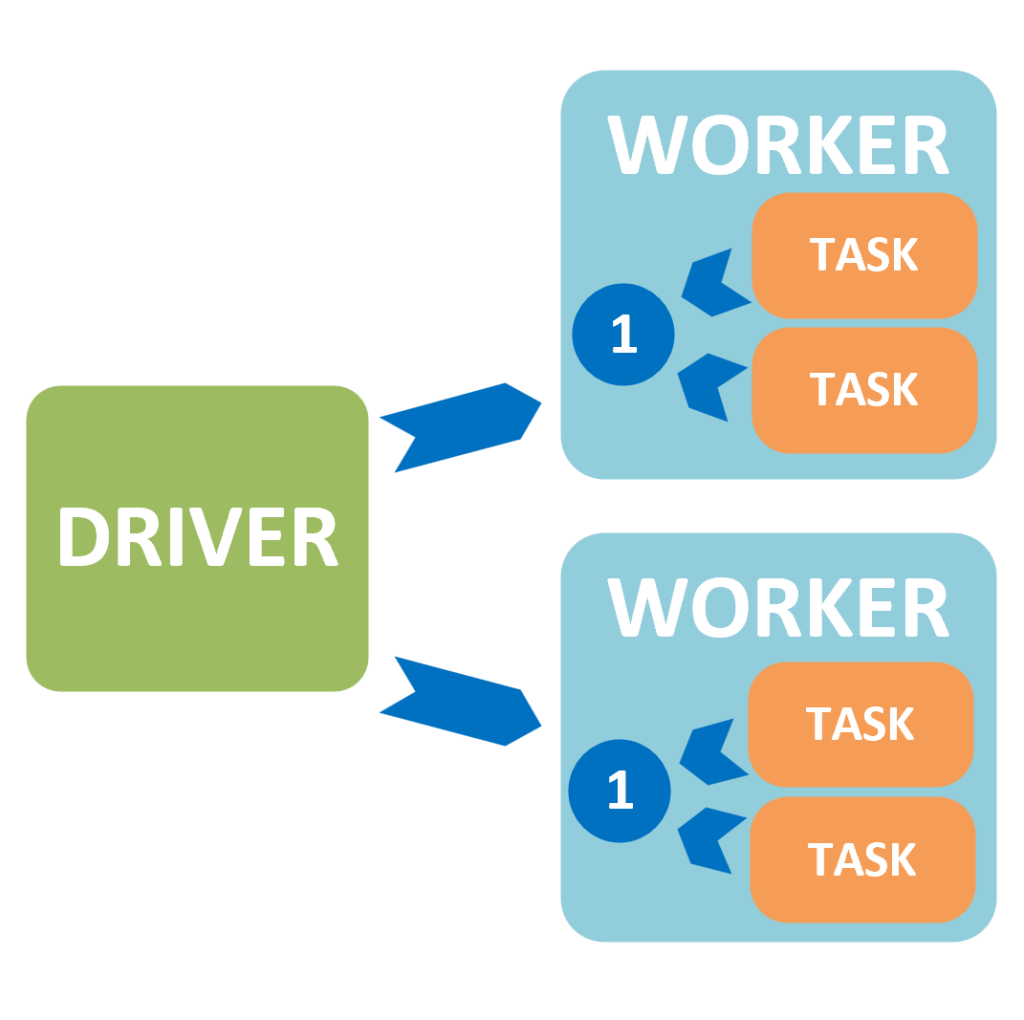

Using a Broadcast Variable, the lookup Table 1 can be made available for each Executor to read rather than be read from the driver multiple times. This is really useful to reduce network traffic.
Accumulator Variables
Whereas Broadcast Variables are used for reading across your Worker Nodes in a cluster, Accumulators are used for writing across the Nodes back to the driver.

Accumulators are used to gather together partial values across many tasks across the executors. They can be added to by the executors but only read by the driver (see Accumulator 2 in the diagram above). These are often used for Counters or Sums for example.
Sample

This a function which was something that featured frequently across numerous questions in the Practice Exams. If you are someone from a more Data Engineering background performing Dataframe transformations, you may not have considered the use of this.
The syntax for this method is as follows:
sample(withReplacement, fraction, seed=None)
withReplacement: bool #Can rows appear more than once?
fraction: float #Fraction of rows to generate
seed: int #Seed for sampling (to lock random number generation)
Looking at the following sample question as an example:
What would be the correct code block for returning 250 rows of a 1000 row Dataframe, assuming that returned rows are distinct and the sample is reproduceable?
df.sample(True, 0.25, 3456) # Incorrect: Multiple rows can be selected
df.sample(False, 0.25, 3456) # --- CORRECT ---
df.sample(False, 250, 3456) # Incorrect: There should be a fraction of the whole dataset
df.sample(False, 0.25) # Incorrect: No Seed is selected, not reproducible
Cluster Execution Modes
There are three valid execution modes in Spark: Cluster, Client and Local.
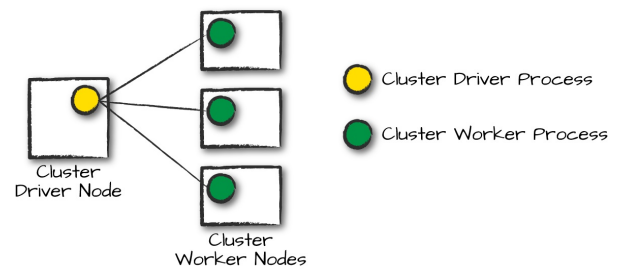
A Cluster Driver and Worker – Spark: The Definitive Guide
These different modes dictate where the driver or resources are located when you run your application.
Cluster Mode
In Cluster Mode, the job is submitted to the Cluster Manager which then launches the Driver and the Executors on Worker Nodes within the Cluster.

Cluster Mode – Spark: The Definitive Guide
Client Mode
Client Mode is where the Spark Driver is located on the machine that is submitting the application and is not located with the cluster. This is often referred to as a ‘gateway machine’ or ‘edge node’.
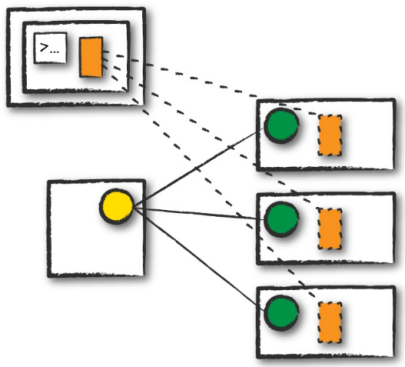
Client Mode – Spark: The Definitive Guide
Local Mode
Local Mode is different from the previous two as it runs the entire Spark Application on a single JVM (Java Virtual Machine).
See Spark: The Definitive Guide (Chambers, Zaharia 2018) – pg.254-256 ‘Execution Modes’
Persist & Cache

Persist and Cache are methods which are often used to optimise operations on the cluster. If a computation of an RDD, Dataset or Dataframe is going to be used multiple times it may be more efficient to save to memory. There are differences that are important to know when considering this approach .
cache() vs persist()
Cache
Caching is done across the workers but using Lazy transformation therefore it will only happen once an action has been performed.
df.cache()
df.count() # An action needs to be performed
Persist
Persisting, however offers options around what type of Storage Level you want.
df.persist(StorageLevel.MEMORY_ONLY)
# The type of Storage Level can be specified
If you want to remove a Dataframe, remove all blocks for it from memory and disk by using unpersist().
When to Cache and Persist?
If a Dataframe is accessed Commonly for frequent transformations during ETL pipelines.
When Not To Cache and Persist?
If there is an inexpensive transformation on a Dataframe not requiring frequent use, regardless of size.
Learning Spark (Damji, Wenig, Das, Lee 2020) – pg.187 ‘When to Cache and Persist’
Storage Levels
Following on from the previous point, Persist() allows for multiple Storage Levels to suit requirements. There may be times when you need to manually manage the memory options to optimise your applications.

Here are the Storage Levels:

Extra Note: Each Storage.Level also has an equivalent ‘LEVEL_NAME_2‘ (e.g. MEMORY_ONLY_2), which means that it is replicated twice on different Spark Executors. This may great for fault tolerance however can be expensive.
Good Luck
Hopefully these last two articles have helped in explaining some of the core components that may feature in your exam. As I said in the previous post, I completely recommend practice exams to really get a sense of what topics you need to revise.
So when you feel ready, register to sit your exam from the Databricks Academy and good luck!