



After diving in to (and passing!) the Associate Developer for Apache Spark 3.0 exam certification from Databricks, I thought it would be useful to go over some quick points to remember and some potential ‘gotcha’ topics for anyone considering the challenge.
The majority of the exam (72% in fact) features the use of the Dataframe API and if you are a person who uses Databricks/Spark regularly, you probably will feel pretty optimistic about these questions. Where I experienced the difficulty often came from the other categories of the exam:
Spark Architecture: Conceptual understanding – 17%
Spark Architecture: Applied understanding – 11%
These sections which I’m going to collectively refer to as just Spark Architecture, are aspects that you may have overlooked especially if you are exclusively using Spark in the context of the Databricks platform.
Firstly, I would recommend you run through a few practice papers before booking your examination, just to really get a feel for the questions and the overall requirements. I tried a few and aside from the Practice Exam provided by Databricks Academy (https://tinyurl.com/5dvjnbkz), my favourite set of papers were written by Florian Roscheck (Senior Data Scientist at Henkel), available in Python or Scala.

https://www.udemy.com/course/databricks-certified-developer-for-apache-spark-30-practice-exams/
Check out these great practice exams on Udemy! Not only are all the answers fully explained on review of the completed paper but also included is an additional third exam which is designed specifically to be more challenging than the actual exam. It was a great chance to really expand my knowledge in preparation for it. If you can achieve passing marks (70% or higher) in paper 3 then you should feel really confident to book in for the actual assessment.
The second aspect to definitely practice before your exam is the use of Spark Docs. You are provided with a copy within the assessment terminal but search is deactivated! The documentation is extensive and the viewing window is super small.
https://www.webassessor.com/zz/DATABRICKS/Python_v2.html
Here is a link to the docs so you can have a try to retrieve the information for various functions using just the scroll bar. This can be hugely important as a number of questions are designed to show function arguments in an incorrect order or with a slightly different name. Having the chance to check if the expression is expecting a String, a Column or a List can be crucial.
Topics to Remember
Over the course of my preparation for the exam I made a few notes on key areas from the Spark Architecture and Dataframe API which I noticed made an significant appearance. So perhaps this pseudo-cheat-sheet may help you to get a better understanding of these components…
Narrow & Wide Transformations
Transformations are interpreted lazily so therefore a list of these processing steps are compiled but will not return an output until they have been initiated by an Action. Transformations come in two distinct categories known as Narrow and Wide.
Narrow Transformations
This is when a change to an input partition will only contribute to one output partition.
Narrow Transformation
# An example of a Narrow Transformation is Filter
df.filter(col("chosenCol") >= 3)
Wide Transformations
This is when a transformation with have input partitions that can contribute to many output partitions.
Wide Transformation
As this operation can span across partitions, this will trigger a shuffle (the reorganisation or partitions of data across nodes in the cluster). This will be important to remember if there is a question relating to execution performance
# An example of a Wide Transformation is Join df.join(newdf, df.id == newdf.id, "inner")
Actions
…And Actions are the triggered computation of our Transformation. This occurs with the initiation of operators like Count() or Collect().
# An example of an Action is Count df.count()
For more information see Spark: The Definitive Guide (Chambers, Zaharia 2018) – pg.25 ‘Transformations’
Spark Execution Hierarchy
So when an Action has been triggered, The Spark application formulates all of the lazily evaluated Transformations in to an Execution Plan to be divided amongst its cluster resources. How is the plan arranged you ask?
Well, it’s simple if you remember “jst these three parts”…
Job – Stage – Task
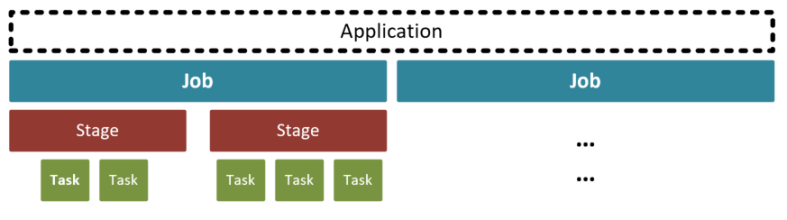
Spark Execution Hierarchy
The Application triggers a Job to fulfil the action.
-
Components of the plan are assembled in to Stages which dependent on shuffles required.
-
The stages are collections of Tasks to run transformations on the divisions of the data which are then sent to the Executors.
For more information see Spark: The Definitive Guide (Chambers, Zaharia 2018) – pg.263 ‘A Spark Job’
Repartition & Coalesce
coalesce()
# vs
repartition()
These are interesting operations because on the surface, they sound like they do the same thing. Collectively they are used to change the number of partitions of a RDD, Dataframe or Dataset however there are some noticeable differences:
Coalesce – Used to decrease number of partitions quickly avoiding shuffles.
# Reduce df partitions to 4 with Coalesce
df.coalesce(4)

Repartition – Can increase and decrease the number of partitions and organises them to an even size. This will result in slower performance due to the full shuffle.
# Reduce df partitions to 4 with Repartition
df.repartition(4) # Optional partition columns can also be specified

Catalyst Optimizer
In order to allow Spark SQL to be as effective as possible the Catalyst Optimizer was created to automatically analyse and rewrite queries to execute more efficiently.

Catalyst Optimizer Diagram
The Catalyst Optimizer takes a computational query and converts it into an execution plan which goes through four transformational phases:
-
Analysis
Spark SQL generates an abstract syntax tree (representation of the structure of text) for the query and converts this to an Unsolved Logical Plan. An internal Catalog (repository of all table and DataFrame information) is then consulted and if a required table or column name does not exist in the catalog, the analyser may reject the plan.
-
Logical Optimization
The optimiser will construct a set of multiple plans and uses its cost-based optimizer (CBO) to assign costs to each plan and applies the processes of constant folding, predicate pushdown and projection pruning to simplify.
-
Physical Planning
Catalyst then organises how the the most efficient logical plan will be executed on the cluster by creating physical plans.
-
Code Generation
The final phase involves the generation of efficient Java bytecode to run on each machine within the cluster.
This can be demonstrated by the joining of two dataframes in this query:
joinedDF = users
.join(events, users("id") ===events("uid"))
.filter(events("date") > "2015-01-01")
For more information see:
Spark: The Definitive Guide (Chambers, Zaharia 2018) – pg.62 ‘Overview of Structured API Execution’
Learning Spark (Damji, Wenig, Das, Lee 2020) – pg.77-81 ‘The Catalyst Optimizer’
https://databricks.com/blog/2015/04/13/deep-dive-into-spark-sqls-catalyst-optimizer.html
In the Next Post…
Check out my next post “Tips for the Databricks Certified Associate Developer for Apache Spark 3.0 – Part 2” where I’ll cover topics such as Cluster Execution Modes, Broadcast Variables and Accumulators!