



How does clustering work, and why is it so important for businesses?
This article provides a straightforward and easy-to-understand explanation of what clustering is and how it is now being used in the business world to address various problems.
What exactly are clustering algorithms?
Clustering, or cluster analysis, is an unsupervised machine learning method. As the name implies, unsupervised machine learning refers to how the model 'learns' the data. It is a learning process opposite to supervised learning. With supervised learning, models are trained or "supervised" using labelled datasets (a known function output to our data). An example of a supervised learning method is where a model is trained to recognise animals based on their labels of being a cat, dog and rabbit.
Unsupervised learning works with unlabelled data where there are no known function outputs, and the aim is to identify patterns within a dataset. There are many unsupervised learning algorithms, however, the three main types are clustering algorithms, dimensionality reduction and anomaly detection. The focus of this blog will be on clustering, as it is the most commonly used unsupervised learning technique.
We will describe the concept of clustering using a simple example and explain how clustering techniques are used in businesses.
Clustering aims to identify patterns from data by dividing them into clusters. Data points assigned to a particular cluster share similar attributes with one another to those outside the cluster. For example, the diagram below shows three distinct clusters (differentiated by colour). Each cluster contains points that have been grouped based on similar values or attributes. Unlike supervised learning, clustering works on unlabelled datasets or has no target variable and is also known to be technically more challenging than supervised learning.
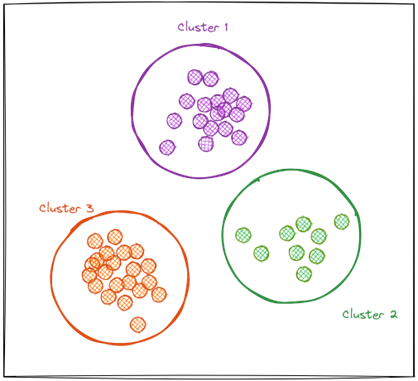
Let's describe clustering using a simple example.
Let's pretend that you are the owner of a shop selling children's toys. The toy shop has many types of different toys, from soft toys to construction toys. However, all these toys in the shop are not organised into sections and are in a complete mess!

Your goal is to organise the toys into three sections; (1) a section for soft toys, (2) construction toys and (3) electronic toys. These toys have no labels, so there is no way to tell which section or category they belong in. Therefore, you have to group them based purely on their features.
You start organising the soft toy section by looking for toys with the same features as a soft toy. Toys that are soft, made of textile, and look like animals or cartoon characters would be what you would look for.
You now move on to organising the construction toys section. The huge box of toys has many toy sets with building blocks used for construction play. You quickly group these sets together into the construction toy section.
Finally, you come to the electronic toy section. This will be easy, as electronic toys are generally noisy and easily discernible from other toys.
You're done, and now the toy shop is organised and looks much better.
What you have just done is clustering! You have grouped the toys into sections that have similar characteristics to one another.
How is clustering used in businesses to solve problems?
Clustering is an incredibly useful technique used across many industries and businesses. In machine learning tasks, clustering is often used in one of two ways.
-
As a tool that is used on its own to solve problems related to identifying patterns within datasets.
-
As a pre-processing step for various machine learning algorithms.
Let's explore how clustering is used to solve problems related to identifying datasets' patterns.

Customer segmentation
Customer segmentation: Clustering is often used to group customers based on their demographics or purchasing behaviour. By segmenting customers into groups, targeted promotions can be done. For example, in the retail industry, customers are often segmented so that their behaviours are well understood. Once the segmentation is performed, targeting a particular segment with group-specific action like promotions can be easily carried out.
Image segmentation: This is a process of partitioning an image into multiple distinct regions containing sets of pixels with similar attributes. Often, this technique is used in medical research to identify underlying patterns and in the automotive industry, in particular in autonomous vehicles to identify objects.

Image segmentation

Market segmentation
Market segmentation: Market segmentation helps businesses increase the chances of people engaging with advertisements or content, resulting in more efficient campaigns and improved return on investment. Similar to customer segmentation, clustering is widely used in many businesses to perform market segmentation.
Anomaly detection: Anomaly detection is another clustering use case that is widely used in businesses, particularly in social media, finance, healthcare and manufacturing. Identification of fake news, fraudulent transactions, or defective mechanical components are popular areas where clustering is often used to detect anomalies. For example, in the finance sector, clustering is often used to identify fraudulent transactions using historical fraudulent transaction data.

Anomaly detection

Document sorting
Document sorting: Clustering can be used to organise and categorise documents based on certain key features, for example, category, keywords, word frequency or content. This is popular within many businesses, where managing risk and compliance is essential.
Pricing: Grouping new products based on a set of features using clustering is often used in the retail industry to price new products accurately.
Customer services: With more emphasis being put on customer care, clustering is widely used to group customer complaints into tiers of importance. This then provides the ability to understand, prioritise and focus on the most important issues to make the most significant impact.

Customer services

Genome analysis
Genome analysis: Clustering is often used to determine similarities between genomes. In fact, clustering algorithms were utilised during the Covid-19 pandemic to detect and analyse distinct strains of Coronavirus to help establish similarities to origin hosts.
Let's explore how clustering is used as a pre-processing step for various machine learning algorithms
Often clustering algorithms are used as a pre-processing step before implementing a supervised algorithm. For example, when you are classifying a large dataset for which the labels for the entire dataset are unavailable, then using a clustering technique can help. It will aid in clustering the dataset without labels into groups based on similar features, which can be used as input to a classification model.
Another example is where clustering is used to remove outliers in the dataset to reduce the size and complexity of the dataset for classification purposes.
There are many more use cases and applications where clustering has been leveraged in businesses. Hopefully, the above examples provide a good idea and understanding of how clustering has been used to tackle various issues.
Wrapping up
In this post, we introduced the concept of clustering, an unsupervised machine learning approach, and demonstrated how it has been utilised to tackle a variety of issues.
In the next article, we will delve a little deeper into clustering algorithms and explain the top 10 clustering algorithms that are often used by data scientists and practitioners of machine learning.
