



For any service company that bills on a recurring basis, a key variable is the rate of churn.
Harvard Business Review, March 2016
What is churn?
Customer churn, also known as customer attrition, is when customers stop using a service or product offered by a company. In simplistic terms, it is when a customer leaves or ceases to be a client any longer.

Customer churn rate is a metric commonly used to determine the percentage of customers who end their relationship with a company in a particular period.
Industries such as banks, insurers, gyms, telecommunications, and online streaming providers, for example, all track churn rates. It is one of the most important metrics for a growing business to handle, as losing customers leads to a loss in revenue. It is also one of the most popular machine learning use cases to implement and deploy in businesses.
Why Is Customer Churn Rate Important?
It is one of the most important metric for a growing business to keep a handle on. Research carried out by Frederick Reichheld of Bain & Company (the inventor of the net promoter score) that shows increasing customer retention rates by 5% increases profits by 25% to 95%. And if that was not enough t convince you of the importance of customer retention, Gartner Group statistics found that 80% of a company's future profits are derived from 20% of its existing customers.
Besides increasing profits, understanding the drivers behind churn will also enable businesses to action or do something to stop customers from leaving or stop using a product. This inevitably leads to customer retention and satisfaction improvements by establishing proactive communication with customers.
How are we going to predict churn?
We will build a machine learning solution to predict churn using Azure Synapse Analytics and Azure Machine Learning.
Azure Synapse Analytics is Microsoft's limitless analytics platform that combines enterprise data warehousing and big data analytics. In simple terms, it is a one-stop-shop that allows you to ingest, prepare, and manage data that can then be used for machine learning and business intelligence, all from a single place. It provides a unified platform and encourages collaboration between data and machine learning professionals.
This article will show you how to build an end-to-end solution to train a machine learning model from Azure Synapse analytics using AutoML functionality within Azure Machine Learning. Using the T-SQL Predict statement, we can then use the trained machine model to make predictions against the churn dataset stored in the SQL Pool table. One of the key benefits of working from within Azure Synapse is that all the necessary steps required to train and make predictions with the trained model can be done from a single platform, Azure Synapse.
We can do this in 3 steps which can be summarised as follows:
-
Deploy and set up an Azure Synapse Analytics workspace
-
Train a machine learning model using Azure Machine Learning AutoML with Spark compute
-
Deploy the ONNX model and make a prediction in the SQL Pool database using Synapse Studio
I think with this … we are ready to get started! 😊🙌🏽
1. Deploy and set up an Azure Synapse Analytics workspace
Before we start training a model, we will require to have the following:
-
Azure Synapse Analytics workspace
-
Azure Machine Learning Workspace
-
Setup the Dedicated Serverless Apache Spark Pools** and SQL Pools in Azure Synapse
-
Make sure that a link is created from Azure Synapse to Azure Machine Learning
-
Upload the training and testing datasets
There are many tutorials and step-by-step guides that have detailed how to get started with deploying and setting up Azure Synapse Analytics, along with the necessary steps to create the link to Azure Machine Learning Workspace. I have included the steps along with the links that will guide to getting this set up and ready to go:
-
Create and set up the Azure Synapse Analytics workspace*. For details, see Creating a Synapse workspace
-
Create Dedicated Serverless Apache Spark Pools** and SQL Pools. For details, see Create a serverless Apache Spark pool and Create a dedicated SQL pool
-
Create an Azure Machine Learning Workspace; see Create a new Azure Machine Learning linked service in Synapse
* This creates an ADLS gen2 account associated with Synapse
** One thing to note is that to use the AutoML functionality, we will create an Apache Spark Pool version 2.4 for it to work.
We will be working with "The Orange Telecom's Churn Dataset", which consists of customer activity data (features) and a churn label specifying whether customers cancelled their subscription. This dataset can be downloaded from this link and has already been divided into a training set and a testing set.
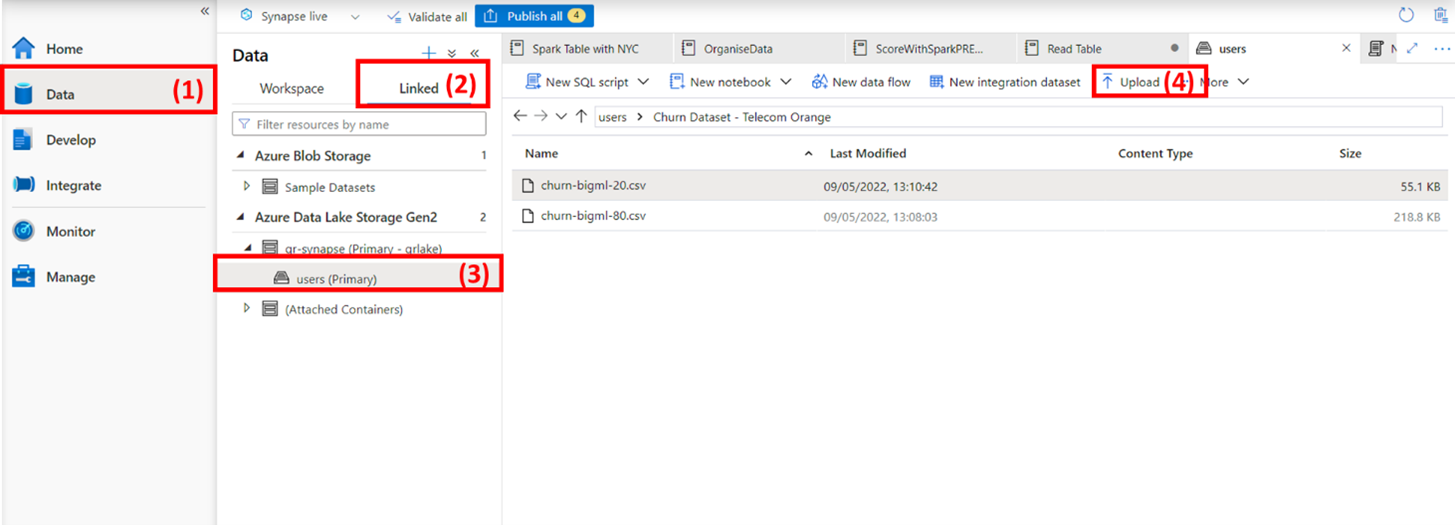
The easiest thing to do is upload both the train and test datasets into the ADLS gen2 account. Navigate to (1) Data navigate to the (2) Linked Workspace. Within the Linked Workspace, you should see the folder created (3) Primary storage – this would have been set when creating the Synapse workspace. Finally, click on (4) Upload to transfer the train and test datasets into the storage folder.
Once we get the files in the folder, the next task is to write the training dataset to the table using the Spark Cluster to be visible within the Lake Database in the Workspace.
The testing dataset will need to be uploaded to the SQL pool database to be used as a test set for prediction.
To do this, we can simply right-click on the (1) Test dataset, select (2) NEW SQL script, and then choose the (3) Bulk load option. The Bulk Load wizard will guide you through creating a T-SQL script with the COPY statement to Bulk load data into a dedicated SQL pool. Synapse will automatically produce a SQL script that, upon running the script, the test data will be created in the SQL Pool database. For more information, see Quickstart: Bulk loading with Synapse Studio.

For the Bulk Load option, ensure that the Infer column names option is enabled so that the names of the columns are automatically detected. When Open script is then selected, a T-SQL script is generated with the COPY statement to load from your data lake.

2. Train a machine learning model using Azure Machine Learning AutoML with Spark compute
We are now ready to train a machine learning model. As the title of this article suggests, we will use a no-code solution to train a suitable ML model. We will leverage AutoML within the Azure Machine Learning Studio platform. By using AutoML, we will be able to train hundreds of thousands of models with a few clicks of a button.
To start AutoML from Synapse, navigate (1) Data, then onto (2) Workspace. Then, (3) right-click on the training dataset to see further options. We need to select (4) Machine Learning and then (5) Train a new model.

Go through the Train a new model wizard and the change the following parameters:
-
Choose a model type: Classification
-
Target column: Churn
-
ONNX model compatibility: Enable
-
Maximum training job time (hours): 2
-
ONNX model compatibility: Enabled (as this will allow deploying the model on the SQL pool)
ONNX is an acronym for the Open Neural Network eXchange and is an open format built to represent machine learning models, regardless of what frameworks were used to create the model. This enables model portability, as models in the ONNX format can be run using various frameworks, tools, runtimes and platforms. By selecting ONNX compatibility, we will be able to import models into our dedicated SQL pool for the T-SQL prediction.
Once we select and fill in all the relevant information, Synapse will communicate with Azure Machine Learning Studio (using the link service connection). You will see a notification that an AutoML job has been submitted. If this is not set up correctly, then Synapse will not be able to communicate with Azure Machine Learning, and you will start seeing errors.
You can now take your much-needed break by making a cup of coffee or tea ☕🍰.
An option here would be to hop on to the Azure Machine Learning platform to check if the AutoML run is in progress or has been successfully completed. The best model will be registered in the Model Registry if the run is completed.
3. Deploy the ONNX model and make a prediction in the SQL Pool database using Synapse Studio
The final step once we have now trained a machine learning model is to deploy the best model into the SQL pool database and to use the model to predict on unseen data, the test data.
Navigate to (1) Data, then select (2) Workspace and then click on (3) SQL database. The test dataset uploaded in the previous step described in "1. Deploy and set up an Azure Synapse Analytics workspace" should be visible in the database. Select the (4) Test dataset and right-click to see further options. We need to perform the prediction based on the trained ML model, so navigate to (5) Machine Learning, then onto (6) Predict with a model.

Next, select your registered model within the Predict with a model wizard. This will open up an input/output mapping window. If everything looks correct, then name your batch prediction script and model registry table. This will create a T-SQL script that will call PREDICT to determine if a customer will churn or not churn.

Selecting Run will output the results as shown below.
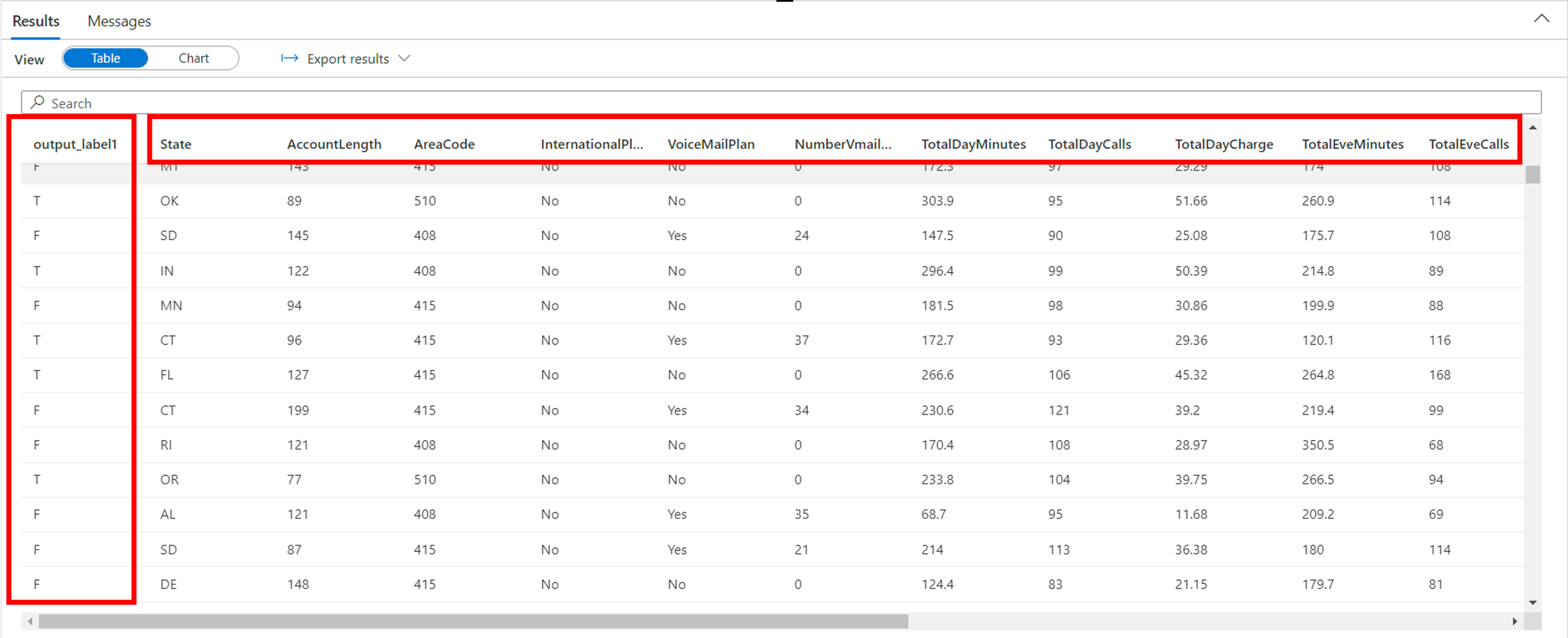
And there we have it! We have successfully predicted churn using Azure Synapse Analytics by leveraging AutoML.
To summarise, this blog describes the meaning of churn, why predicting churn is invaluable and how to predict churn using Azure Synapse and Azure Machine Learning.
