



The execution plans in Databricks allows you to understand how code will actually get executed across a cluster and is useful for optimising queries.
It translates operations into optimized logical and physical plans and shows what operations are going to be executed and sent to the Spark Executors.
Execution Flow
Databricks uses Catalyst optimizer, which automatically discovers the most efficient plan to execute the operations specified.
Catalyst optimizer flow:
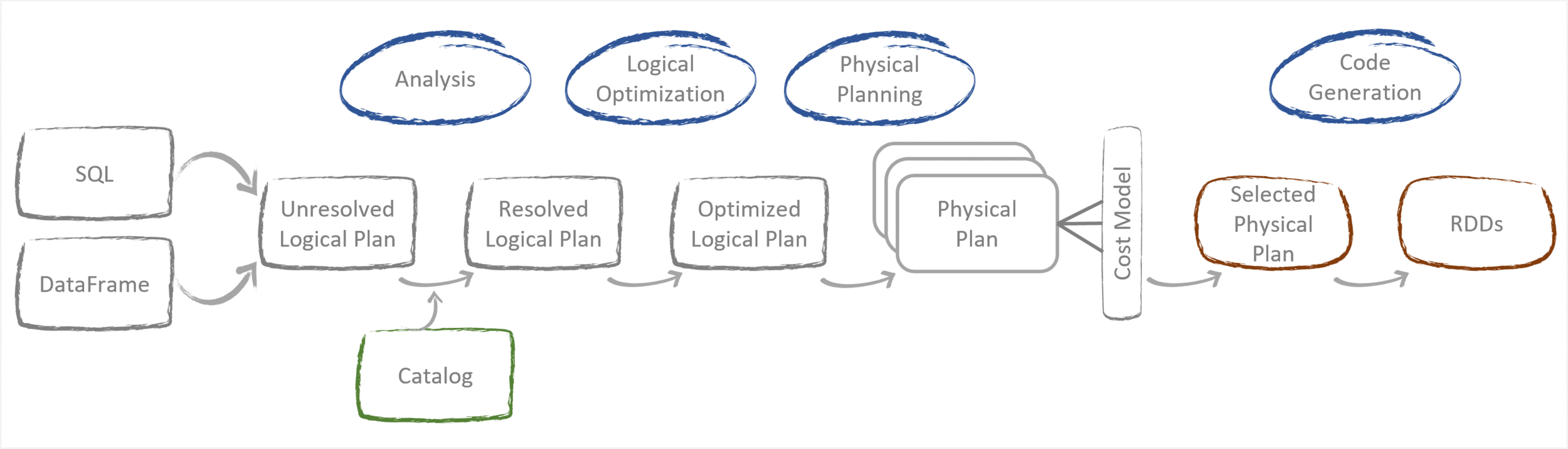
The execution process is as follows:
- If the code written is valid then Spark converts this into a Logical Plan
- The Logical Plan is passed through the Catalyst Optimizer
- The Optimized Logical Plan is then converted into a Physical Plan
- The Physical Plan is executed on the cluster

Execution Plans
The execution plan is made of logical and physical plans.
Logical Plan
The Logical Plan is broken down into three sections:
- Parsed Logical Plan (Unresolved Logical Plan): This is created once the code has been validated and where it is unable to validate a table or column objects it flags them as
Unresolved. - Analyzed Logical Plan (Resolved Logical Plan): Using the
Catalogwhich is a metadata repository of all table and DataFrames, it validates and resolves theUnresolvedtable or column objects identified in previous plan before continuing. - Optimized Logical Plan: Once everything is resolved, the plan is sent to the
Catalyst Optimizerwhich applies predicates or rules to further optimize the plan. Optimize rules can consists of predicate or projection pushdown, reordering operations, conversions and simplifying expressions.
Physical Plan
The Physical Plan is how the logical plan that was created, is going be executed on the cluster.
- The
Catalyst Optimizergenerates multiple physical plans based on various strategies. - Each strategy is assessed through a
Cost Model, establishing estimates for execution time and resources utilisation. - Using the
Cost Modelestimates it determines the best optimal plan/strategy and selects it as theSelected Physical Planwhich is executed on the cluster.
Generate Execution Plans
Both logical or physical plans can be generated using Python or SQL functions, either using .explain() or EXPLAIN functions.
By default, when an argument is not supplied it returns the Physical Plan, if the extended argument is supplied it returns the Logical Plan, showing the Parsed Logical Plan, Analyzed Logical Plan, Optimized Logical Plan and Physical Plan.
Understanding Execution Plans
To demonstrate execution plans, lets create a dataframe where it is joining two Delta tables, applying some filtering and aggregations.
Let’s explore the Logical Plan using the python command and setting extended argument to True.
The first section of the explain output is the Parsed Logical Plan.
This has validated everything and built the first version of the logical plan with the flow of execution (Sort, Aggregate, Filter and Join operations).
It was unable to validate the Join relationship, so it has tagged the Join Relation operation as UnresolvedRelation.

The next section of the explain output is the Analyzed Logical Plan.
This has used the Catalog to validate the table or column objects, so it has now resolved everything it was unable to in the first plan.
You can see that the Join Relation operation that was previously marked UnresolvedRelation is now resolved, it has returned a SubqueryAlias operations from the spark_catalog which has determined the Join relationship.

The next section of the explain output is the Optimized Logical Plan.
As the Logical Plan is now validated, it can optimize the plan based on the operations it needs to perform.
You can see the operations have been reordered, the Filter is now performed as part of the Join operation reducing the volume of data being processed by the join.

The final section of the explain output is the Physical Plan.
Using the optimized logical plan, it has created multiple physical plans, compares them through the Cost Model and then selected the best optimal plan as the Selected Physical Plan which is outputted on screen.
You can now see the cluster operations, the FilesScan with PushFilters, the BroadcastHashJoin and HashAggregate.

Additional Parameters
There is an optional mode parameter that can be used with the .explain() or EXPLAIN functions, that will show different output formats of plans.
.explain(mode="simple"): displays the physical plan, like providing no arguments..explain(mode="extended"): displays both logical and physical plan, like providingTruearguments..explain(mode="codegen"): displays the physical plan and generated codes if they are available.explain(mode="cost"): displays the optimized logical plan and related statistics, if they exist..explain(mode="formatted"): displays two sections splitting Physical Plan outline and node details.
Adaptive Query Execution (AQE)
Adaptive Query Execution can further optimize the plan as it reoptimizes and changes the query plans based on runtime execution statistics. It collects the statistics during plan execution and if a better plan is detected, it changes it at runtime executing the better plan.
This is not displayed when the .explain() or EXPLAIN functions are ran, therefore you will need to explore the Spark UI and tracking the changes.
By default, this feature is disabled therefore needs to be enabled using the Spark Configuration settings.
Spark UI
The execution plans can also be view from the Spark UI on SQL tab under the Details section, once the query has been executed.

Summary
Databricks execution plans are very useful when optimising, to get a better insight on how the query will perform on the cluster and which operation that can be enhanced.
It is easy to obtain the plans using one function, with or without arguments or using the Spark UI once it has been executed.
The Adaptive Query Execution (AQE) feature further improves the execution plans, by creating better plans during runtime using real-time statistics.
Thanks for reading, I hope you found this post useful and helpful.
Example notebooks can be found on GitHub.
References
https://databricks.com/glossary/catalyst-optimizer
https://databricks.com/session/understanding-query-plans-and-spark-uis
https://spark.apache.org/docs/latest/api/python/reference/api/pyspark.sql.DataFrame.explain.html